




SKU:
Pythagorean Theorem Dominoes Activity
$3.50
$3.50
per item
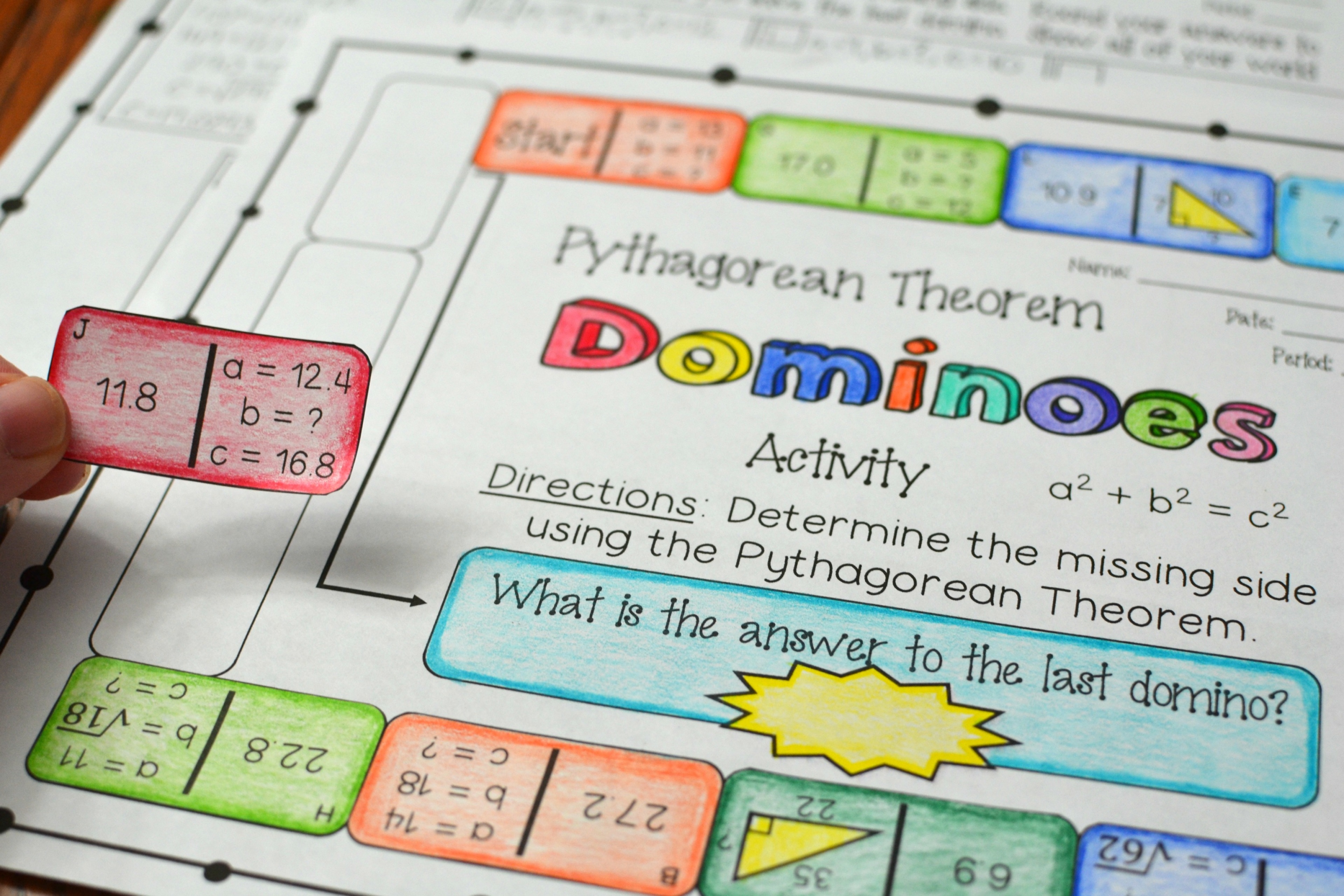
Included is a dominoes activity on the Pythagorean Theorem. Students will be calculating the missing side of a triangle by using the Pythagorean Theorem. Some domino pieces show a picture of a triangle with a missing side. Other domino pieces show a = , b = , and c = with one of these sides unknown. This is a great activity for working in pairs, or small groups.
File Type: PDF
Pages: 4+
Answer Key: Included
File Type: PDF
Pages: 4+
Answer Key: Included